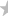


Dans la vie d'un concepteur de logiciels informatiques, il y a des expériences qui semblent revenir assez souvent. Les soucis d'encodage de fichiers textes en font partie ! Quand un programme ne sait lire qu'un type d'encodage alors qu'un autre écrit lui aussi uniquement dans un format d'encodage, mais forcément différent, les problèmes commencent. On pourrait se dire que de nos jours ces problèmes ne devraient plus exister, mais ils subsistent toujours un peu comme une rémanence du passé, un rappel de la longue histoire de l'informatique et des normes qui existent pour ranger les différents caractères.
Encoding Detector offre la possibilité de détecter quelques-uns des formats d'encodage les plus fréquemment utilisés, tout comme les caractères de fin de lignes. Il permet également le ré-encodage vers un fichier de sortie.
Sommaire
Fiche Encoding Detector
2018. WolfAryx informatique
Licence :

Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Configuration requise :
Windows 7/8/8.1/10 (x64/x86), NET Framework 4
Langages supportés :
Français/Anglais/Espagnol (selon le langage du système)
Journal des changements :
- 1.0.0.107 :
- Correction d'un bug sur le caractère de fin de ligne de la dernière ligne.
- Ajout de l'option -a, pour n'afficher que le header/à propos.
- Ajout d'un fichier de script PowerShell ps1 dans l'archive téléchargée, pour lancer le traitement du programme sur un dossier.
- Ajout de la traduction en espagnol "Benvenuti a voi amici spagnoli!"
- 1.0.0.70 :
- Correction d'un bug lorsque la syntaxe était présentée.
- Amélioration de la traduction.
- 1.0.0.59 :
- Corrections orthographiques
- Ajout de la référence vers l'article sur wolfaryx.fr consacré à Encoding Detector (cet article).
- 1.0.0.57 :
- Passage des textes anglais en français.
- Ajout d'une traduction correcte en anglais.
- Langue selon paramètre de Windows.
- Utilisation de codes de sortie.
- Ajout de l'option -p, sortie paramétrable, permettant de personnaliser le texte renvoyé par les traitements.
- Correction sur la détection du caractère de fin de ligne pour l'encodage UTF16BE_NOBOM.
- Ajout de la détection du caractère de fin de ligne Macintosh (avant OSX).
- 1.0.0.48 :
- Ajout de l'option -s, niveau de silence, afin de limiter/contrôler le texte affiché à l'écran.
- Prise en charge de la conversion lorsque le fichier en entrée (-f) est le même que le fichier de sortie (-o).
- Correction qui faisait que lors d'un ré-encodage, si le caractère de fin de ligne cible (-e) n'était pas précisé, le programme n'en mettait pas.
- Correction du ré-encodage qui ajoutait un caractère de fin de ligne à la dernière ligne du fichier ré-encodé.
- Ajout d'une icône pour l'exécutable.
- Pour l'option -o, si le texte "SAME_AS_INPUT" est indiqué, alors le nom du fichier en sortie sera le même que celui en entrée : le fichier en entrée sera remplacé par sa conversion.
- 1.0.0.6 :
- Première version distribuée.
Téléchargement :
- 1.0.0.170 (22/05/2018) : lien md5(1f43013b754bda0a0fc047975c858c7e)
- Anciennes versions disponibles ici.
Code source disponible à cette adresse :
Téléchargement et contenu de l'archive
Le fichier ZIP téléchargé contient les fichiers suivants :
- DetectEncoding.exe : c'est l'exécutable de l'application.
- TextEncodingDetect.dll : En tant que fichier avec une extension dll, il s'agit d'un fichier contenant des fonctions nécessaires pour EncodingDetector. C'est ce qu'on appelle une librairie, car elle contient plusieurs fonctions utiles. Celle-ci contient les fonctions nécessaires pour la détection de l'encodage (github.com/.../text-encoding-detect).
- AryxDevLibrary.dll : Librairie contenant des méthodes de programmation communes que j'utilise dans mes programmes développés en C# (nuget.org/.../AryxDevLibrary / code.dacendi.net/.../AryxDevLibraryCsharp).
- RunForAFolder.ps1 : script PowerShell permettant de lancer le programme sur les fichiers présents dans un dossier. Permets d'exécuter les traitements d'EncodingDetector sur plusieurs fichiers en un seul lancement.
Installation
Hormis la configuration requise, EncodingDetector ne nécessite rien d'autre pour fonctionner. Il n'y a pas d'installation particulière pour que le programme fonctionne, il faut juste extraire l'archive dans un dossier.
EncodingDetector est une application console, c'est à dire qu'elle ne présente pas d'interface graphique. Donc pas de fenêtre Windows; un peu comme NetworkChanger Console. Cela permet une utilisation simplifiée dans divers scripts (Batch, PowerShell, ...).
Capture d'écran du texte affiché par Encoding Detector
Utilisation
Sans interface, EncodingDetector utilise des options d'entrée. La syntaxe générale est la suivante :
DetectEncoding.exe OPTIONS
Avec les options suivantes :
- -f : fichier à traiter.
- -c : encodage du fichier cible.
- -e : caractère de fin de ligne cible.
- -o : fichier cible résultant de la conversion.
- -s : règle le niveau du texte affiché.
- -p : sortie paramétrable (permet de personnaliser la sortie standard).
- -a : à propos.
Détail des options
Fichier à traiter
Option : -f ou --file, option obligatoire (sinon le programme n'a pas de fichier avec lequel travailler)
Description : Indique le chemin du fichier pour lequel il faut déterminer l'encodage et le caractère de fin de ligne.
Conversion de l'encodage
Option : -c ou --convert-to
Description : Spécifie l'encodage cible désiré.
Choix :
- ASCII,
- ANSI,
- UTF8_BOM,
- UTF8_NOBOM,
- UTF16LE,
- UTF16LE_NOBOM,
- UTF16BE,
- UTF16BE_NOBOM
Conversion du caractère de fin de ligne
Option : -e ou --end-of-line-to
Description : Spécifie le caractère de fin ligne cible désiré.
Choix :
- DOS : pour un caractère de fin de ligne CR LF ou encore \r\n . Utilisé dans les produits Microsoft (DOS, Windows).
- MACOS : pour un caractère de fin de ligne CR ou encore \r. Utilisé par les systèmes Macintosh (avant MacOs X)
- UNIX : pour un caractère de fin de ligne LF ou encore \n.
Nom du fichier converti
Option : -o ou --output-file
Description : Nom désiré du fichier converti. Si une des options -e ou -c est utilisée, et que -o est omis, le fichier en sortie aura le même nom que le fichier en entrée, suffixé avec "Out". Si la valeur "SAME_AS_INPUT" est indiquée pour -o, alors le nom du fichier en sortie sera le même que celui en entrée : le fichier en entrée sera remplacé par sa conversion.
Attention : aucune sauvegarde du fichier en entrée n'est effectuée.
Niveau de silence
Option : -s ou --silence-level
Description : Permet de régler le nombre d'éléments affichés dans la console. Selon 3 niveaux :
- 0 : Affiche le texte de présentation de l'application, ainsi que le résultat des traitements. Niveau par défaut.
- 1 : Affiche uniquement le résultats des traitements.
- 2 : N'affiche rien.
Sortie paramétrable
Option : -p ou --output-pattern
Description :
Permet d'effectuer un formatage personnalisé sur la sortie, c'est-à-dire sur ce que le programme renvoie.
La chaine de sortie est personnalisable. Les variables de modèle ci-dessous seront substituées :
- [APP_VERSION] : le numéro de version du programme. Exemple : 1.0.0.59.
- [IN_FILE] : Le chemin du fichier passé en entrée du programme.
- [IN_ENC] : L'encodage du fichier en entrée détecté.
- [IN_EOL] : Le type de caractère de fin de ligne détecté.
- [OUT_ENC] : L'encodage demandé du fichier en sortie. Si aucune conversion n'est effectuée, cette variable sera substituée par une chaine vide.
- [OUT_EOL] : Le type de caractère de fin de ligne demandé pour le fichier en sortie. Si aucune conversion n'est effectuée, cette variable sera substituée par une chaine vide.
- [OUT_FILE] : Le chemin du fichier en sortie. Si aucune conversion n'est effectuée, cette variable sera substituée par une chaine vide.
- [WITH_REENC] : indique si une conversion a eu lieu. true ou false.
- [EXIT_CODE] : le code de sortie du programme.
- [EXIT_CODE_LBL] : le libellé du sortie du programme.
A propos
Option : -a ou --about
Description : Affiche un texte à propos pour le programme. Ne fait rien d'autre.
Affichage des résultats
Affichage normal
Le résultat s'affiche de façon textuelle sur deux lignes minimum.
La première ligne de résultats commence par "InputFile" afin de rappeler le fichier en entrée (définit avec l'option -f).
La seconde ligne indique les résultats des détections selon la syntaxe :
Encoding: [Encodage détecté]; [Caractère de fin de ligne détecté]
Avec :
- Encodage détecté : le type de l'encodage du fichier en entrée. Encoding Detector peut détecter les encodages suivants : ASCII, ANSI, UTF8(avec ou sans BOM), UTF16(LE/BE, avec ou sans BOM).
- Caractère de fin de ligne détecté : le type de caractère de fin de ligne utilisé dans le fichier. Le programme détecte soit le type UNIX ("\n"), MacOs ("\r") ou DOS/Windows ("\r\n").
Si une conversion a été demandée avec les options -c ou -e, alors une troisième ligne similaire à la deuxième apparaitra, mais pour les options de ré-encodage demandées.
Affichage personnalisé
Si l'option -p est précisée, les résultats s'afficheront selon la chaine indiquée en argument de l'option de -p. Cette option permet d'afficher uniquement la partie désirée du résultat, ou même de formater le résultat.
Voir exemple 4.
Codes de sortie (ou d'état)
Encoding Detector utilise des codes de sortie, ou codes d'état, afin d'indiquer à un programme parent ou appelant les tâches qui ont été effectuées. Les codes suivants sont utilisés :
- Traitements terminés avec succès :
- 0 : Détection OK. Le programme n'a réalisé que la détection. Aucun ré-encodage n'était demandé,
- 1 : Détection et ré-encodage OK,
- 2 : Affiche du texte "à propos",
- Traitements terminés, mais le résultat n'est pas complet :
- 20 : Aucun encodage n'a été détecté sur le fichier d'entrée.
- Traitements en erreurs :
- 50 : Erreur sur les options passées en entrée du programme,
- 51 : Erreur au niveau de la détection de l'encodage,
- 52 : Erreur au niveau du ré-encodage,
- 99 : Erreur non prévue.
Avec l'invite de commandes Windows, le code de sortie peut être affiché avec la commande suivante (après avoir lancé Encoding Detector) :
echo %ERRORLEVEL%
Avec PowerShell, le code de sortie est contenu dans la variable $LASTEXITCODE. Pour l'afficher, utilisez la commande suivante (après avoir lancé Encoding Detector) :
$LASTEXITCODE
ou
write-host $LASTEXITCODE
Exemples
Exemple 1
Commande :
.\DetectEncoding.exe -f .\fichierAnsi.txt
Sortie écran :
Encoding Detector - v1.0.0.56
===================================
par Aryx - WolfAryx informatique - 2018
Détection de l'encodage basée sur les travaux de AutoIt Consulting :
https://github.com/AutoItConsulting/text-encoding-detect
InputFile: C:\EncodingDetector\fichierAnsi.txt
Input : ANSI; DOS
Ici, l'encodage du fichier "fichierAnsi.txt" est détecté comme de l'Ansi. Son caractère de fin de ligne est "\r\n", de type Dos/Windows.
Exemple 2
Commande :
.\DetectEncoding.exe -f .\fileTest.sql -c UTF8_BOM -e UNIX
Sortie écran :
Encoding Detector - v1.0.0.56
===================================
par Aryx - WolfAryx informatique - 2018
Détection de l'encodage basée sur les travaux de AutoIt Consulting :
https://github.com/AutoItConsulting/text-encoding-detect
InputFile: C:\EncodingDetector\fichierAnsi.txt
Input : ANSI; DOS
Output: UTF8_BOM; UNIXIci,l'encodage du fichier "fichierAnsi.txt" est détecté comme de l'Ansi. Son caractère de fin de ligne est "\r\n", de type Dos/Windows. Le fichier de sortie sera encodé en UTF8 avec BOM et avec un caractère de fin de ligne de type Unix "\n".
Comme l'option "-o" n'a pas été précisée, le fichier de sortie se nomme :
fichierAnsi-Out.txt
Exemple 3
Commande :
.\DetectEncoding.exe -f .\fichierAnsi.txt -c UTF8_BOM -e UNIX -s 1 -o "fichierConvertiUTF8.txt"
Sortie écran :
InputFile: c:\EncodingDetector\fichierAnsi.txt
Input : ANSI; DOS
Output: UTF8_BOM; UNIX
Ici, le résultat de cet exemple est similaire à celui de l'exemple 2. Seuls changements, l'ajout de l'option "-s" valorisée à 1, ainsi que l'option "-o" indiquant le nom du fichier après conversion.
Comme "-s" égale 1, le texte de présentation de l'application n'est plus affiché.
En indiquant "fichierConvertiUTF8.txt" pour l'option "-o", le fichier de sortie ne s'appellera pas "fichierAnsi-Out.txt" mais "fichierConvertiUTF8.txt".
Exemple 4
En lançant le programme avec la commande suivante :
.\DetectEncoding.exe -f .\file-ANSI-Test.txt -c UTF8_BOM -e DOS
-p "[WITH_REENC]([EXIT_CODE]) - [IN_ENC] vers [OUT_ENC]:[OUT_EOL]"Le programme n'affichera que :
true(1) - ANSI vers UTF8_BOM:DOSEncoding Detector a effectué les remplacements suivant dans la chaine modèle de l'option "-p" :
- [WITH_REENC] a été remplacé par true (indique qu'un ré-encodage a été effectué),
- [EXIT_CODE] a été remplacé par 1 (encodage et ré-encodage ok),
- [IN_ENC] a été remplacé par ANSI (encodage du fichier texte en entrée),
- [OUT_ENC] a été remplacé par UTF8_BOM (encodage du fichier en sortie),
- [OUT_EOL] a été remplacé par DOS (caractère de fin de ligne en sortie).
Remarques sur la détection de l'encodage d'un fichier
Qu'est ce qu'un encodage de caractères ?
Un fichier texte est un fichier comprenant du texte, c'est-à-dire une suite de caractères. Ces fichiers sont bien souvent lisibles humainement, mais pas forcément. Cependant, ils ont en commun d'être lisible selon un encodage particulier. En effet, la base de tout ce qui est codé en informatique c'est le bit : 0 ou 1. Une suite de 0 et de 1 permet de donner un sens à une information : cela peut être une instruction pour programme, le contenu numérique d'un fichier image, ou encore du texte.
Pour que les ordinateurs puissent comprendre qu'une suite de 0 et 1 alignés d'une façon particulière puisse signifier une suite de caractères, il a fallu établir des conventions : c'est ce qu'on appelle l'encodage pour un fichier texte. Ainsi, avec l'encodage ASCII (un des plus anciens) la suite de bits suivantes :
01010111 01101111 01101100 01100110 01000001 01110010 01111001 01111000
Permet en fait d'écrire :
WolfAryx
C'est quand même déjà plus simple à lire que des 0 et des 1 ! Mais pour les adeptes du binaire (l'écriture de 0 et de 1), j'ai regroupé les 0 et les 1 par paquets de 8 (ce regroupement s'appelle un octet). Avec ces octets, on peut remarquer que chaque lettre de "WolfAryx" est codé par 1 octet. On a donc 8 octets pour les 8 caractères.
Dans cet exemple, l'encodage des caractères s'appelle l'ASCII. Un encodage créé en 1963 par des américains et qui permet de coder 128 caractères. Avec si peu de caractères, cet encodage n'était pas adapté aux pays utilisant des lettres accentuées et n'était pas du tout utilisable pour les langues asiatiques, arabes etc. C'est pour prendre en charge toujours plus de caractères que sont apparus d'autres formats d'encodages par la suite.
Si l'histoire des encodages de caractères vous intéresse, je vous recommande l'excellent article publié sur ZesteDeSavoir qui détaille précisément l'histoire et les enjeux de ces formats : https://zestedesavoir.com/tutoriels/1114/comprendre-les-encodages/.
Pour finir, on appelle un fichier "non texte" : un fichier binaire : c'est à dire dont le contenu n'est pas une suite de caractères. Ces fichiers servent souvent de conteneur pour stocker de la musique, des images, du code informatique compilé, etc : ce sont vos fichiers mp3, avi, png, jpg...
Limite de la détection de l'encodage
Il existe donc plusieurs normes de codage des caractères en informatique. Et pour faciliter les choses, il n'y a bien souvent pas de façon d'indiquer avec quel encodage est écrit un fichier texte. Heureusement, la plupart des encodages sont basés sur l'ASCII. De fait, les caractères simples, non accentués, sont facilement interprétables par les programmes informatiques. Reste le souci des caractères "supplémentaires" comme les caractères accentués.
D'où la nécessité de détecter l'encodage d'un fichier texte. La plupart des éditeurs de texte ont cette fonctionnalité. Notepad++ par exemple affiche l'encodage ainsi que le caractère de fin de ligne dans la barre d'état en bas à droite.
Mais cette détection se base la plupart du temps sur une approche statistique en parcourant le texte à la recherche des caractères pouvant influer le choix vers tel ou tel encodage. C'est ce qui fait que la détection d'encodage utilisée par Encoding Detector, ou par n'importe quel programme informatique, n'est pas fiable à 100%.
Le plus simple dans le cadre de travaux informatiques étant souvent de coordonner les choses : imposer l'utilisation de tel ou tel encodage au sein d'un projet est une solution qui permet d'éviter bien des soucis !




